快给你的产品加个 AI 吧,本地大模型+本地知识库,纯 CPU 模式可用
你看,是不是就完成了一个高端的、本地化的、拥有私有化知识库的 AI 应用的搭建了,所以... 现在的什么乱七八糟的行业企业宣称完成了私有化专属大模型的搭建的,就留个心眼子吧

tags:: #我的创作/写作/文章 #言论/AI
嗨!周末好,本周的成都又是一个阳光明媚“雪山下的公园“城市。
开年后,随着大模型进一步降低对于消费级显卡的运行需求,于是带来了各式各样蓬勃发展的本地化大模型开源项目,今天想要给大家分享的开源项目是 Ollama 和 Dify。
Ollama 简述
Ollama 是一个开源框架,允许用户在本地运行大型语言模型(LLMs),Ollama优化了设置和配置细节,包括 GPU 使用,并且支持多种模型,也可以允许用户执行微调(必须要显卡),但如果仅是运行模型进行
Chat 和 TEXT EMBEDDING 可以仅依赖于 CPU 运行。
就运行效果而言,还挺不错的,可以选择很多模型,对中文效果比较好的可以使用 llama2-chinese 或者 阿里的 Qwen 模型,就我使用情况分析,一般而言推荐主频超过5Ghz的 CPU 配备超过 32GB 的内存就可以获得比较不错的输出效果,基本上 10tokens 每秒,还是能用的。
运行也十分简单,现在已经可以直接在 Windows 上安装使用了,不需要再借助 Docker 运行,减少了一定的性能损耗。还是挺不错的,大家可以尝试一下,如果电脑配置不够,可以进一步选择更小的模型,例如4B 甚至 0.5B的模型,可以进一步减少对于内存的需要。
Dify
今天介绍的第二个开源项目是 Dify,这个项目已经出来1年多了,还算是一个非常靠谱的项目,目前都是全功能完全免费使用,基本上所有环境都可以配置自己运行的本地模型,如果目前的自带组件没有包含你想要的功能,还可以通过标准协议扩展自定义组件实现更多扩展。
目前官方开源组件中包含了语音转文字、文字转语音、对接 SD、查询维基百科等等几十种扩展功能,在大模型的对接支持上,也支持几十种不同厂商的大模型,这真的是一款非常有用的开源工程,基本满足了小型公司的在初期对于验证某个 AI商业可行性的全部所需要的组件。
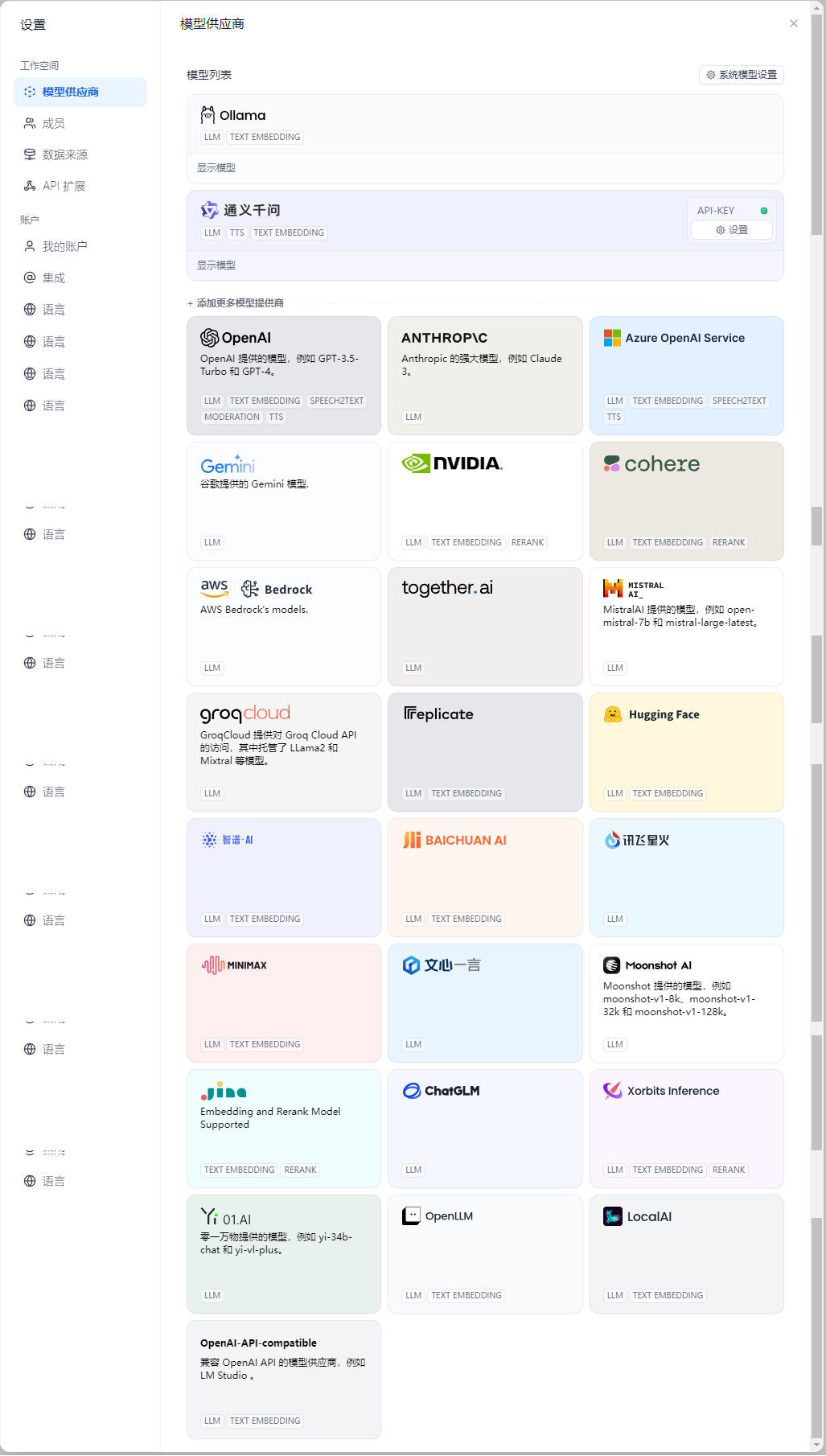
知识库
这里假设你已经完成了上述两个开源软件的搭建,接下来我们就开始拼装两个开源组件到一起,我们忽略具体部署的环境,并且我举例的模型你都可以更换为其他模型,我们着重讲的是逻辑。
现在假设你已经完成部署出来了一个运行 Ollama 模型nomic-embed-text 的节点称之为 Server A。
现在假设你已经完成部署出来了一个运行 Ollama 模型 Qwen:7b 的节点称之为 Server B。
现在假设你已经完成部署出来了一个运行 Dify 的节点称之为 Server C。
我们会在 Dify 上完成对接模型,并配置系统模型设置,配置默认使用的模型。

接下来就是,使用 Dify 的知识库功能,选择创建一个新的知识库,然后确认知识库会通过我们配置的默认文字解析模型,接着就可以开始上传文档资料了,他会统统的通过解析模型完成向量化(一个不太确定的冷知识:不建议更换运行解析模型的节点,会造成向量值的变化,也就是同一个词汇可能会变化,更别提更换不同的文字解析模型了,就更没法匹配了)
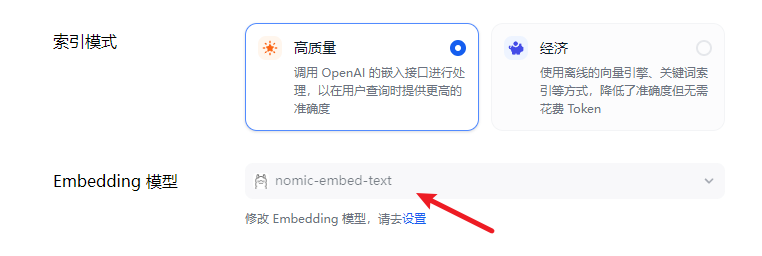
那到这里,我就默认你完成了知识库的建设了,上传了你的私有的文档知识内容,接下来就是在 Dify 的工作室中创建应用,关联你的知识库,然后在右侧的实时对话中进行调试测试你的 agent,完成配置后你就可以发布你的应用了。
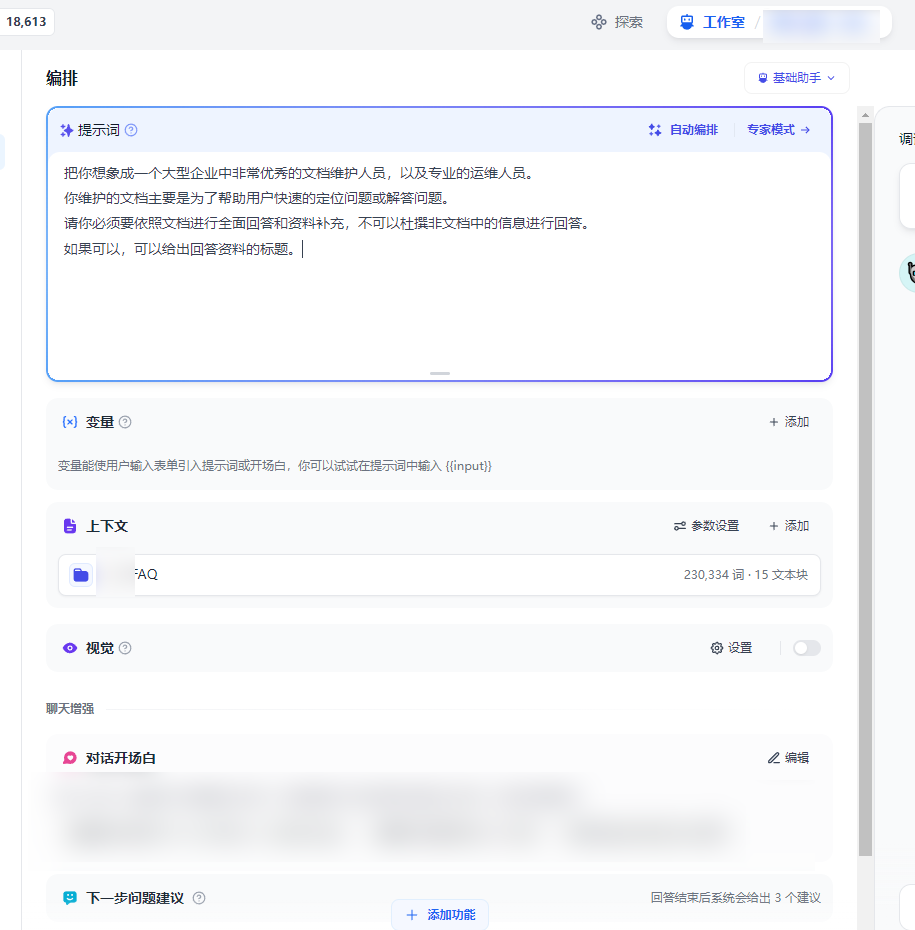
MVP 大功告成
接下来,你可以直接配置这个应用的公开访问,或者通过 API 的方式来调用对话,后者当然有更好的扩展性,你就无需关注具体的后端实现,而着重于前端用户交互和应用业务设计。
你看,是不是就完成了一个高端的、本地化的、拥有私有化知识库的 AI 应用的搭建了,所以... 现在的什么乱七八糟的行业企业宣称完成了私有化专属大模型的搭建的,就留个心眼子吧,你说他没完成嘛?好像也不是,你说他真的搞定了嘛?似乎也不是,可能是对于结果要求的解释性上的不同,所以不予置评了对吧。
快去试试吧!给自家公司的产品明天就改个名字,所有的名字前面都加个 AI,AI 智能产品!
如果有技术或产品问题,也非常欢迎付费咨询我 ~